( ^∇^)✎.....
Intro
강화학습(Reinforcement Learning)의 기본 아이디어는 "일단 해보자"는 것이다.
그리고 강화학습의 목표는 "Maximize Reward"이다.
이 아이디어와 목표가 합쳐지면?
일단 해보면서, 더 많은 보상을 받을 수 있는 답을 찾아내는 것이 된다.

위 그림은 강화학습의 과정에서 발생하는 에피소드의 흐름을 나타내고 있다.
가장 큰 그림을 보면, 이 햄토리는 관찰의 결과에 따라 환경을 조작하는 행동을 하고 있다.
조금 더 자세히 들여다보면, 이 관찰과 행동을 하기 위해서는 어떤 상태에서 어떻게 행동해야 더 많은 보상을 받고 더 적은 패널티을 받을 수 있는지를 아는 판단력이 필요하다는 것을 알 수 있다.
여기서 "관찰과 행동"이라는 그 과정을 반복하면 행동에 변화가 나타나고 판단력이 강화될 것이다. (정확히는 [판단력 강화 → 행동의 변화] 순서가 될 것이다)
용어를 정리해보자.
여기서의 이 판단력과 위에서 말한 답을 정책(policy)이라고 한다. (행동의 근거로 삼는 규칙이라 볼 수 있다)
그리고 행동(action)의 주체이자 학습하는 대상인 햄토리를 에이전트(agent)라고 부른다. (햄토리는 보통 알고리즘이 될 것이다)
Agent와 Environment가 서로 상호작용하며 정보(state, reward)를 주고받는 구조이고, 결국 Environment의 State에 따라 더 많은 Reward을 받을 수 있는 Action을 Agent가 할 수 있도록 하는 Policy을 만드는 것이 목적이 된다.
이렇게 강화학습은 선택한 행동에 대한 환경의 반응인 보상을 통해 학습하는 방식으로, 상황에 대한 정보 없이 환경을 정확히 알지 않고도 시행착오만으로 기능을 학습할 수 있다.
Markov Process


앞으로 강화학습이 풀 문제들은 모두 MDP로 표현될 것이다. 먼저 "MDP"의 기반이 되는 Markov Process부터 이해해 보자. 위 정의에서 체인 또는 연쇄라는 단어는 시간의 진행에 따라 상태가 확률적으로 변화하는 "Process"를 의미하고 있다. 미리 정의된 확률분포를 따라 상태 사이를 이동하는 과정이기 때문이다. 이에 대한 확률론적인 접근에서는 어떠한 확률 분포를 따르는 random variable이 discrete한 time interval마다 값을 생성해내는 것을 의미한다.
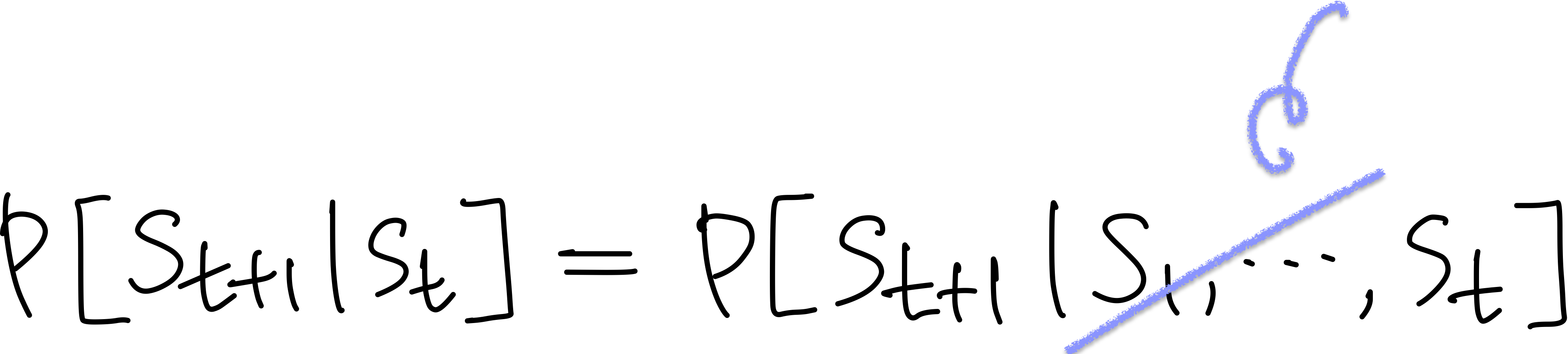
다음으로 "Markov"하다는 것은 state가 관련된 history 정보를 모두 가지고 있다는 의미를 담는다.
Markov property를 가지는 것은 이전에 어떤 state를 거쳐왔든 다음 state로 갈 확률은 항상 같다는 것을 보장하며, "현재 상태가 주어졌을 때 미래와 과거는 독립적이다"는 가정을 의미하기도 한다. (이러한 무기억성의 성질에 따라 Memoryless Property로도 불린다) i.e. The state is a sufficient statistic of the future... Once the state is known, the history may be thrown away...Ꮚ
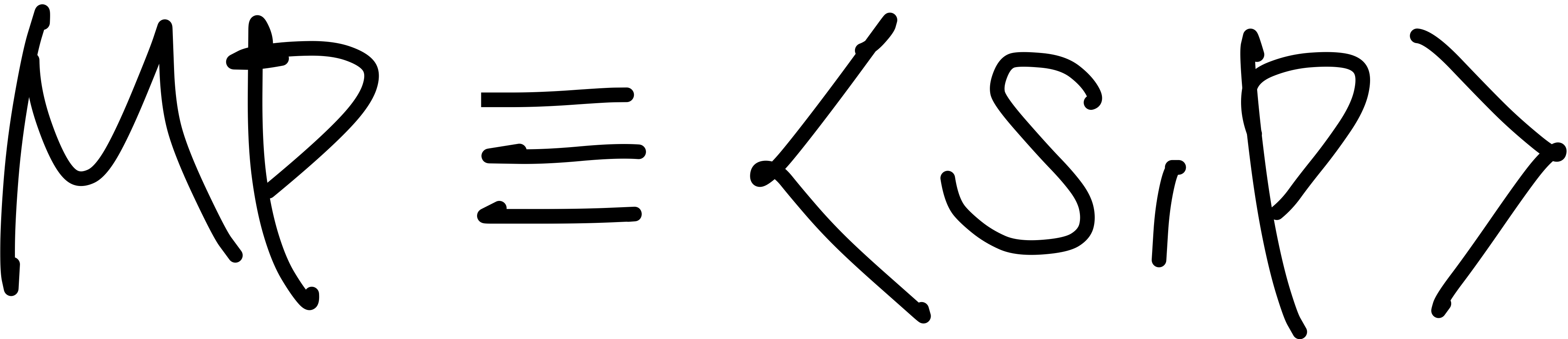
그렇기에 확률론에서 Markov Proecess는 메모리를 갖지 않는, 이산 시간 확률 과정이라고 정의하며, 상태들의 집합 $S$와 전이 확률 행렬 $P$의 두 가지 요소를 가지는 튜플로 표현한다.

Markov한 state $s$에서 다음 state $s'$로 이동할 확률을 나타낼 수식은 위와 같다. (상태전이확률)
state $s$에서 action $a$를 취했을 때 reward $r$을 얻으면서 next state인 $s'$로 간다는 의미를 더 디테일하게 담아 $P(s',r|s,a)$로도 표현한다. (MDP)
✔️Markov Reward Process

상태 전이가 얼마나 가치 있는지를 정량화해서 나타내기 위해서는 Reward라는 개념이 필요하고, 이 개념을 MP(Markov Process)에 도입한 것을 Markov Reward Process, 즉 MRP라고 한다. MRP에서는 state $s$에서 action $a$를 했을 때 얻을 보상인 $R(s,a)$을 이용해 state의 가치를 판단할 수 있다.

이렇게 MRP는 보상 함수 $R$과 감쇠인자 $\gamma$가 추가된 튜플로 표현된다. $\gamma$의 도입에 대한 설명은 Goal of RL 및 Q-learning 파트에서 자세히 나오므로 "더 미래에 얻을 보상에 더 많이 곱해지면서 그 가치(중요도)를 낮추는 역할을 하는 값" 정도로 이해하고 넘어가자.

✔️Markov Decision Process
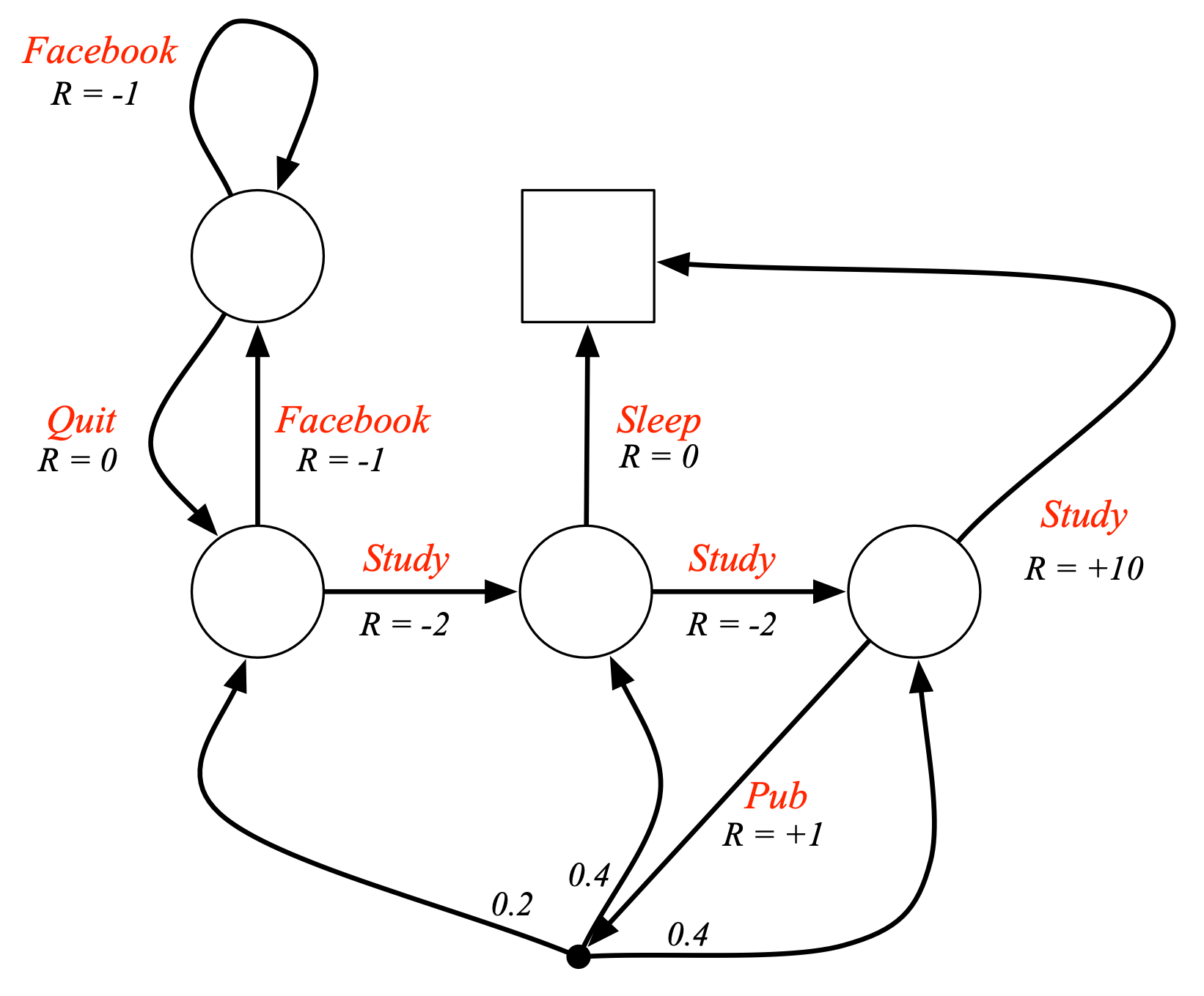
강화학습은 순차적으로 행동을 결정해야 하는 문제를 푸는 것이다. 그러한 문제를 클래식한 수식으로 나타낸 것(형식화한 것)이 MDP이기 때문에 강화학습을 MDP의 문제를 푸는 것이라고 표현하게 된다. 전이 확률에 따라 상태변화가 자동으로 이루어졌던 MP, MRP와는 달리 의사결정이 핵심이 되는 MDP에서는 에이전트가 하는 행동에 의해 상태가 변한다. 따라서 MP에 Action(의 집합)이라는 요소가 더해진 튜플로 표현되고, 추가로 policy라는 개념이 포함된다.

다만 에이전트가 어떤 행동을 했을 때, 그것이 꼭 원하는 방향으로의 결과를 보장하지는 않기에 (🌬️바람이나 오작동…) state $s$에서 "action $a$를 했을 때" state $s'$로 상태가 전이될 확률을 정의한다. 마찬가지로 선택하는 action에 따라 reward가 달라지는 MDP에서는 보상 $R$에도 state $s$의 가치뿐만 아니라 action $a$의 가치에 대한 판단이 들어가, "action $a$를 했을 때"가 포함된 수식으로 나타낸다.


위에서 설명했듯이, 판단력에 해당하는 policy는 어떤 state일 때 어떤 action을 할지를 결정(mapping)하는 것이다. 즉 policy는 state $s$에서 action $a$를 수행할 확률이므로 수식적으로는 다음과 같이 조건부 확률 형태로 표현한다.

Goal of RL
이쯤에서 강화학습의 목표를 다시 한번 생각해보자.
Reward를 maximize한다는 강화학습의 목표를 달성하기 위해서는 어떤 policy가 그 역할을 수행할 수 있을지 찾아야 한다. 그런데 정확히는 Reward들의 합인 "Return"을 maximize하는 것이 강화학습의 목표이고, 더 정확하게는 Return이 가중치의 개념을 적용한 "discounted reward의 sum"이라고 정의된다.

이렇게 discount factor $\gamma$를 이용해 먼 미래에 얻을 보상에 비해 가까운 미래에 얻을 보상의 크기를 작게 두는 것이고, 그에 따라 Return $G_t$는 수식적으로 다음과 같이 표현한다.
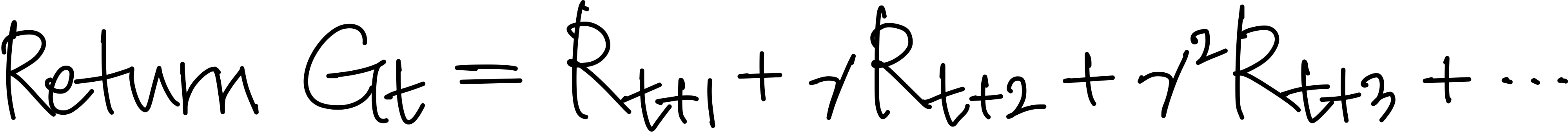
($t$시점의 state $s$와 action $a$에 따른 Reward를 $t+1$ 시점에 받는 것으로 생각하여 $R_{t+1}$로 표현한다)
그런데 action과 state가 random하게 선택되는 경우가 포함되기 때문에 그에 따른 reward도 random variable이라고 볼 수 있다. 따라서 그 평균값을 취한 평균 리턴값을 maximize 해야하고, 위와 같은 리턴 $G_t$의 정의에 따라, Expected Return을 나타내는 가치함수는 다음과 같이 정의된다.

정리하자면, 강화학습은 Expected Return을 maximize하는 것이 목표이고, 그러한 목표를 달성하는 액션을 할 수 있는 policy(distribution)을 찾아나가는 것이다.
Value Function
Expected Return을 잘 표현하는 방법은 두 가지가 있다.
✧ State Value Function(상태가치함수)
지금부터 기대되는 Return으로, state $s$에서 policy $\pi$에 따라 쭉 행동할 때 기대되는 가치를 말한다.
즉, 현재 state에 대한 가치를 매겨주자는 것이다.
$$ v_{\pi}(s)=\mathbb{E}_{\pi}[G_t\,|S_t=s] $$
✧ Action Value Function(행동가치함수)
지금 행동으로부터 기대되는 Return으로, state $s$에서 특정 action $a$를 했을 때 얻을 수 있는 가치를 말한다.
$$ q_{\pi}(s,a)=\mathbb{E}_{\pi}[G_t\,|S_t=s,A_t=a] $$
MRP에서는 state에 대한 value만 판단할 수 있었다면, MDP에서는 action에 대한 value도 판단이 가능하기에 이 가치함수들을 이용하게 된다. 지금까지 학습한 개념들의 활용은 다음과 같다.

먼저 $t$시점에 state $s$에 놓인 agent가 policy에 따라 action $a$를 하면, 그렇게 수행한 action에 대한 reward를 받는 동시에 transition probability에 따라 state $s'$로 이동하게 된다. 이 과정에서 SVF와 AVF는 각각 state와 action에 대한 가치를 판단하는 역할을 한다.
Bellman Equation
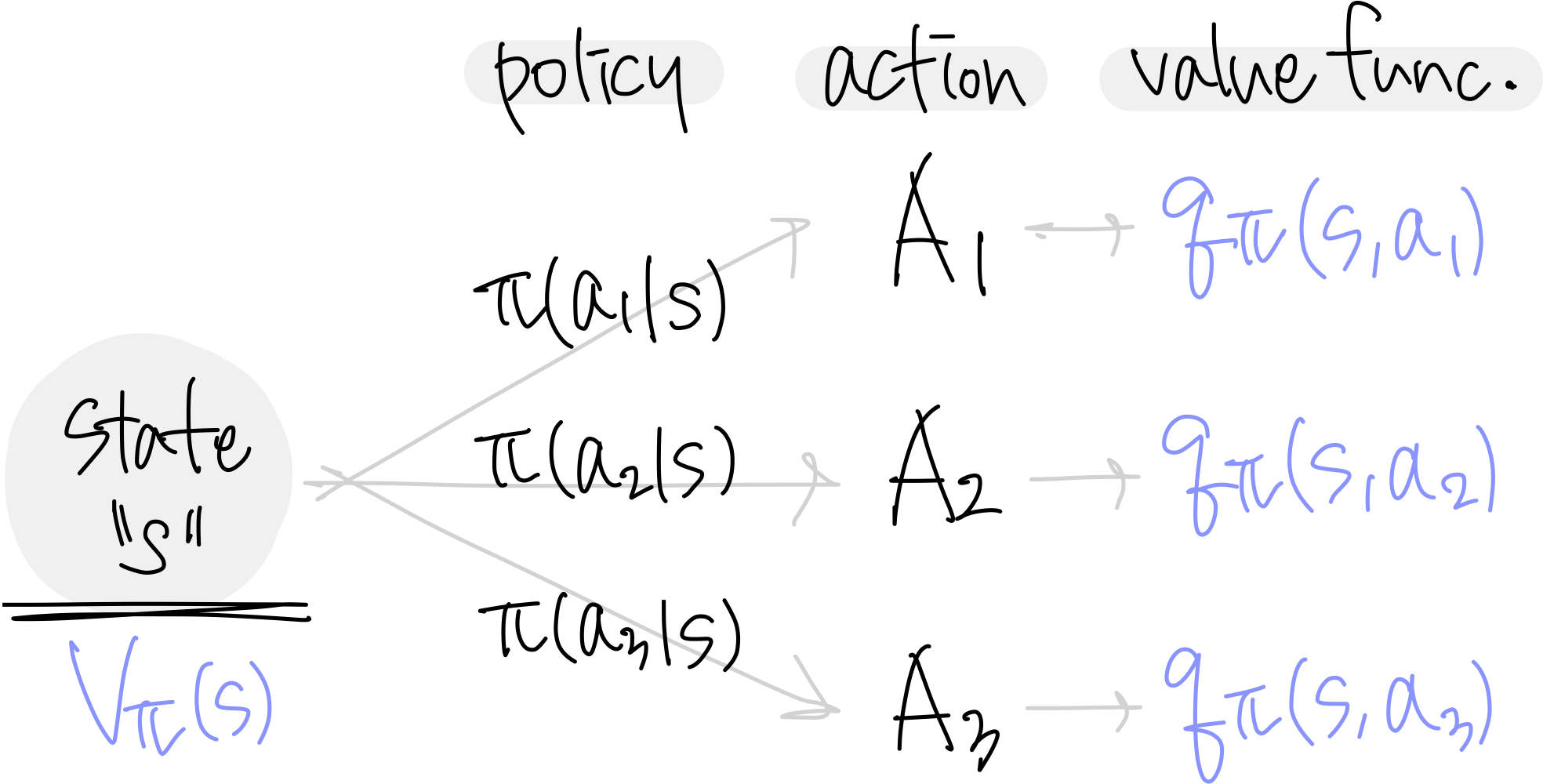
그렇다면 state $s$의 가치는 어떻게, 어떤 기준으로 판단할 수 있을까?
$s$에서 할 수 있는 모든 action들에 대한 가치를 반영하기 때문에 다음과 같이 각 action을 할 확률(policy)와 그 action의 value function을 곱한 것의 합으로 표현할 수도 있다.
$$ V_{\pi}(s)=\sum_{a\in A}\pi(a|s)\cdot q_{\pi}(s,a) $$
$V_{\pi}(s)$는 state $s$에서 할 수 있는 모든 action들에 대한 value(action value)의 평균이라는 뜻을 담고 있는 수식이 된다.
마찬가지로 action value function을 다른 방식으로 구해보자

AVF는 어떤 action에 대한 가치를 구해주는 것이기 때문에, state $s$에서 action $a$를 했을 때의 reward와 그 다음 state가 될 $s'$의 value function의 합과 같다. ($V_{\pi}(s')$는 $t+1$ 시점에서의 value function이므로 discount factor를 적용해준 것이다) 또한 deterministic한 환경이 아니기에 상태 전이($s \rightarrow s'$)에 대한 확률도 적용시켜주면, 다음과 같은 식이 도출된다.
$$ q_{\pi}(s,a)=R_s^a + \gamma \cdot \sum_{s'\in S}P_{ss'}^a \cdot V_{\pi}(s')$$
결국 $P_{ss'}^a=p(s',r|s,a)$이라는 점을 고려하면 다음과 같은 식으로 표현이 되더라도 이해할 수 있을 것이다.
$$ q_{\pi}(s,a)=\sum_{s',r}p(s',r|s,a)[r+\gamma v_{\pi}(s')] $$
action들은 stochastic하기 때문에 $p(s',r|s,a)$의 확률을 가지고, 해당 action을 통해 다음 state에서 바로 얻을 가치인 $p(s',r|s,a)*r$와 action을 통해 이동한 다음 state $s'$의 가치를 계산한 $p(s',r|s,a)*\gamma v(s')$가 있다.
이 두 가지 가치를 합친 것이 action a의 총 가치가 된다.
벨만 방정식이란 무엇일까?
특별한 것이 아니라, 지금까지 등장한 식들만으로 설명이 가능하다. SVF와 AVF 사이의 관계로 만들어지는 현재 state/action와 다음 state/action의 관계식을 벨만 방정식이라고 한다. 그리고 강화학습은 이러한 벨만 equation을 푸는 과정이라고 볼 수 있다.
$V$(state value function)를 $q$(action value function)로 표현할 수 있고, 반대로 $q$를 $V$로 표현할 수 있다는 점을 이용해 $V$를 next $V$로, $q$를 next $q$로 표현할 수 있는 방정식이 벨만 방정식(BE)이다.
그러므로 $q_{\pi}(s,a)$로 표현된 state value function $V_{\pi}(s)$에 action value function의 식을 대입하면 다음과 같은 새로운 svf를 구할 수 있다.
$$ V_{\pi}(s)=\sum_{a\in A}\pi(a|s) (R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a V_{\pi}(s')) $$
같은 방법으로 action value function에 state value function을 대입하여 recursive한 형태로 표현된 새로운 avf를 구할 수 있다.
$$ q_{\pi}(s,a)=R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a \sum_{a\in A}\pi(a'|s') q_{\pi}(s',a') $$
그렇다면 현재와 바로 다음 state에서 가치함수의 관계를 알 수 있는 이 Bellman Eqn.을 어떻게 활용할까?
당연히 강화학습의 목표인 최대 Reward를 얻기 위해, 최대 reward를 얻는 policy를 찾는 데에 활용한다.
이 방정식은 value function의 초기화된 값(0 or random number)을 계속해서 update하여 "true" value function으로 다가가도록 하는 데에 의미가 있다. 어떤 state에서 어떤 action을 하는 것이 좋은지에 대한 판단 근거가 되는 svf와 avf를 Bellman eqn.으로 업데이트하는 과정을 반복하다 보면, 최대 reward를 얻도록 하는 action들을 선택하도록 하는 optimal policy를 찾게 될 것이다. 그리고 optimal policy를 따르는 벨만 방정식을 BOE(Bellman Optimality Equation)라고 한다.
그렇지만 결국 BOE는 모든 경우의 수를 다 보는 탐색 방법(exhaustive search)과 같기에 좋은 방법이라고 볼 수 없다.
그래서 우리는 "근사(approximation)"라는 것을 이용해야 하고, 그 대표적인 근사 방법이 DP이다.
Dynamic Programming
DP는 알고리즘 문제에서 많이 다뤘듯이, 풀기 어려운 문제를 작게 나눠서 푸는 방법이 그 핵심 아이디어이다.
✦ Policy Iteration ✦
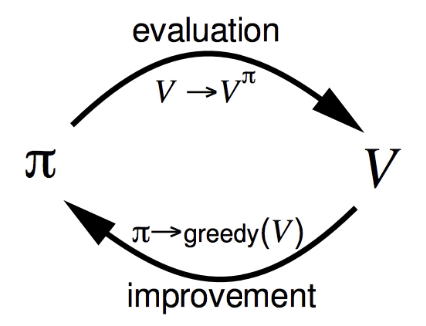
우리의 정책 $\pi$가 최적이 아닌 이상, 우리는 정책 평가를 통해 정책을 향상시켜야 한다.
정책 평가라는 것은 정책을 통해 가치를 얻는 과정이고, 정책 향상은 얻어진 가치에서 탐욕적으로 선택해 반영하는 것이다.
그리고 최적 정책이 될 때까지 정책 평가와 향상을 반복하는 것이 정책 반복이다.
✧ Step 1 >> Policy Evaluation
$$ v_{\pi}(s)=\mathbb{E}_{\pi}[G_t\,|S_t=s] $$
$$ \pi \rightarrow v_{\pi} $$
정책 평가란 어떤 정책($\pi$)에 대한 상태 가치(state value, $v_{\pi}$)를 찾는 것으로, 가치함수(true value function)을 찾는 것을 목표로 한다.
✧ Step 2 >> Policy Improvement
$$ \pi'=greedy(v_\pi) $$
{policy 평가하고, 가치에 따라 greedy하게 움직이는 policy 만들기}라는 set을 반복하면 최적 policy로 간다.
이 두개가 합쳐져 optimal policy를 찾아나가는 과정인 policy iteration이 수행된다.
처음에는 멍청한 value function $v$와 멍청한 policy $\pi$가 있을 것이다. 여기서 이제 $v$를 평가하고, (즉 value function을 구하고) 그에 따라 greedy하게 움직이는 $\pi$를 찾고, 그 $\pi$에 대해서 또 평가하고 ($\pi$가 바뀌었으므로 vf도 바뀔 것이기 때문), 또 greedy하게 움직이는 policy를 만들고, $\cdots$ 이 과정을 반복한다. 그러면 결과적으로 $v$가 $v*$에 도달할 것이다. 그 말은 즉 optimal value라는 것을 뜻한다.
$$ \pi_0 \rightarrow v_{\pi_0} \rightarrow \pi_1 \rightarrow v_{\pi_1} \rightarrow \cdots \rightarrow \cdots \rightarrow \pi_* \rightarrow v_{\pi_*} $$
이렇게 과정을 반복하다 보면 policy가 더이상 update되지 않는 순간이 올 것이고, 그때의 $\pi$와 $v_{\pi}$를 optimal이라고 한다.
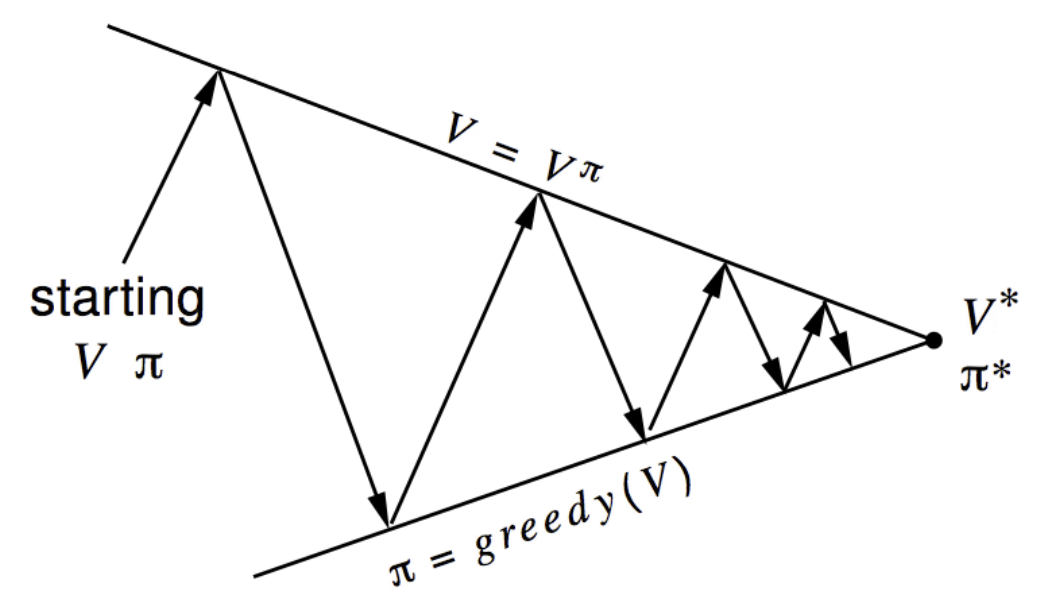
✦ Value Iteration ✦
Policy Iteration이 $v$를 구하고 $\pi$를 update하는 과정이었다면, Value Iteration은 policy에 관심을 주지 않고 그냥 최대 가치를 가지고 바로 value를 update하는 것이다. 즉 $\pi$를 update하지 않고(평가와 개선을 번갈아하는 과정), $v*$를 iterative하게 찾아 나가는 과정(평가와 개선을 동시에 하는 과정)이라는 점에서 차이가 있다.
Optimal Policy
$$ S_t, a_t, S_{t+1}, a_{t+1}, S_{t+2}, a_{t+2}, \cdots $$
이렇게 진행되는 상황에서 Optimal Policy, 즉 최적의 정책은 무엇일까.
과거는 잊고, 지금부터 기대되는 Return을 maximize하자는 의미에서 svf를 maximize하는 것이 최적의 policy가 된다.
svf를 다시 한번 살펴보자
$$ V(S_t)=\int_{a_t:a_\infty}G_t\cdot P(a_t:a_\infty|S_t)\,d_{a_t:a_\infty} \\ = \underset{P(a_t|S_t)}{\mathrm{argmax}} \int_{a_t}Q*(S_t,a_t)P(a_t|S_t)d_{a_t} $$
*표시는 optimal을 말한다.
가치함수 $V(S_t)$가 최대가 되게 하는 policy가 있다면 이제는 $Q*$를 maximize하는 것이 best가 된다.
$Q*(St,at)$라는 최적의 값만 계속해서 뽑아주는 PDF라면, 즉 이 값만 집요하게 sample하는 distribution이 있다면 그것이 best optimal이 될 것이다.
그 말은 곧 $Q*$를 maximize하는 것이 best이기 때문에 수식으로 나타내면 다음과 같다.
$$ a_t^*=\underset{a_t}{\mathrm{argmax}}Q*(S_t,a_t) $$
결론은 "$Q*$를 maximize하는 $a_t$를 고르세요" 가 되고, 이는 곧 action이 optimal policy가 된다는 말과 동시에 $a_t^*$를 찾아야 한다는 것으로 이해할 수 있다.
( ^∇^)✎..... Part 2에서 계속.....
Reference
혁펜하임의 “트이는” 강화 학습 (Reinforcement learning)
팡요랩 강화 학습의 기초 이론 (David Silver 강의 내용 기반)
⌜파이썬과 케라스로 배우는 강화학습⌟, 위키북스
sumniya.tistory.com/category/Reinforcement%20Learning/Contents
sonsnotation.blogspot.com/
댓글