Intro
마지막 10장에서는 더 다양한 그래프 알고리즘들을 알아볼 것이다.
서로소 집합
서로소 집합이야 공통 원소가 없는 두 집합을 의미하는 것이고, 서로소 집합 자료구조가 몇몇 그래프 알고리즘에서 사용된다. 서로소 부분 집합들로 나누어진 원소들이 있을 때, 이 데이터들을 처리하기 위한 자료구조를 union(합집합) 연산과 find(찾기) 연산으로 조작할 수 있다. 이 자료구조를 구현할 때에는 트리 자료구조를 이용해 집합을 표현하는데, 그 알고리즘은 다음과 같다.
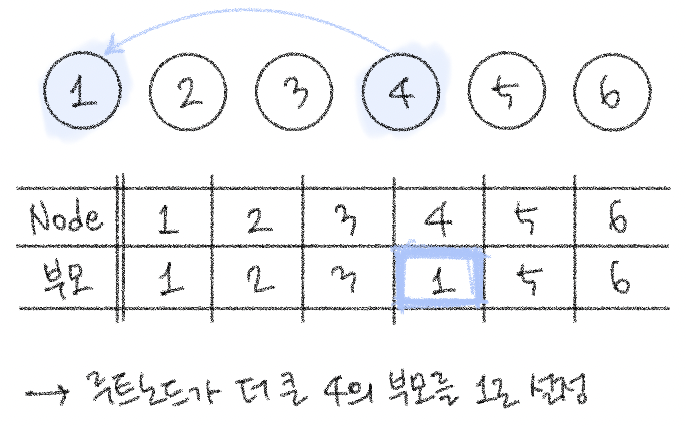
𝟙. union 연산을 확인하여, 서로 연결된 두 노드 A, B 확인
✧ A와 B의 루트 노드 A', B'을 각각 찾기
✧ A'를 B'의 부모 노드로 설정하기 (B'가 A'를 가리키도록)
→ 보통 구현에서는 번호가 더 작은 원소가 부모 노드가 되도록 한다.
𝟚. 모든 union 연산을 처리할 때까지 𝟙의 과정 반복 *-*

.
.
① 기본적인 서로소 집합 알고리즘
Disjoint_basic.py
# 서로소 집합 (basic)
# 입력
# v e
# a b -> e개의 세트
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
if parent[x] != x:
return find_parent(parent, parent[x])
return x
# 두 원소가 속한 집합을 합치기
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
# **
if a < b:
parent[b] = a
else:
parent[a] = b**
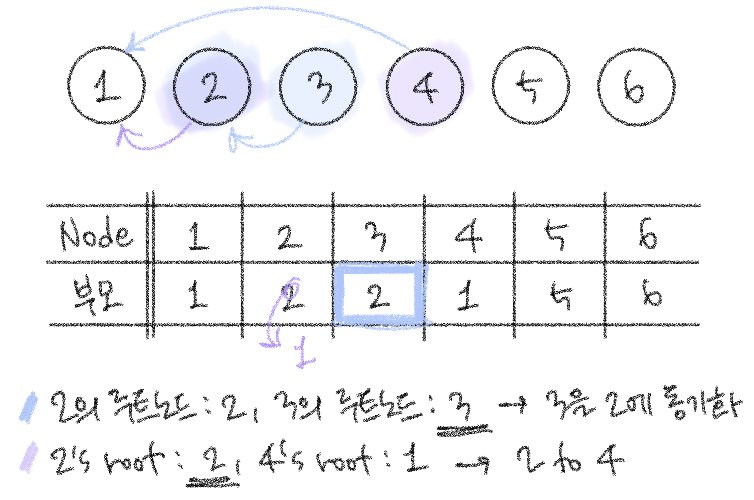
# 여기서 왜 a = parent[a], b = parent[b]를 안하고 이러케 하는가?
# union 2,4를 수행하는 단계를 보면, "2 4"가 입력될 시점의 2의 루트노드는 2이고 4의 루트노드는 1이다.
# parent에 입력된 값과 똑같은데 ...?라고 하기엔 아직까지는 문제가 없는 상황이기 때문
# union 2,4까지 거치게 되면 1,2,3의 부모노드가 각각 1, 1, 2이다.
# 근데? 예를 들어 다음으로 union 1.5,3를 수행할때, (a, b를 parent 정보로 정하면)
# 3의 부모노드 2가 1.5의 부모노드 1.5보다 크다고 3의 부모를 1.5로 설정하게 된다.
# 이렇게 되면 3이 1, 2와 끊어지게 되므로 (다른 집합이 됨) 망함
② 개선된 서로소 집합 알고리즘
find 함수에 경로 압축 기법을 적용해보자. 왜냐면 기존의 방법은 다소 비효율적이기 때문이다. 예를 들어, 1~5번 노드에 대한 부모 노드가 각각 1, 1, 2, 3, 4인 상황에서 노드 5의 루트를 찾기 위해서는 "node 5 → node 4 → node 3 → node 2 → node1" 순서대로 부모 노드를 거슬러 올라가야 하므로 최대 $O(V)$의 시간이 소요될 수 있고, 결과적으로 M개의 find 및 union 연산까지 고려하게 되면 전체 시간 복잡도는 $O(VM)$이 되어 최적화가 필요해 보인다. 일단 개선시킨 알고리즘은 다음과 같다.
Disjoint_adv.py
# 서로소 집합 (advanced)
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]٩( ᐛ )
이렇게 find 함수를 재귀적으로 호출한 뒤에 리턴하지 않고 바로 부모 테이블값을 갱신하면, 함수 호출 이후에 해당 노드의 루트 노드가 바로 부모 노드가 된다. union 함수를 처리하고 find 함수를 수행했을 때 형성된 부모 테이블이 다음과 같이 달라지면서 기본적인 알고리즘에 비해 시간복잡도가 개선된다.

신장 트리
Spanning Tree란 ! 하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미하는, 그래프 알고리즘 문제로 자주 출제되는 문제 유형이다.


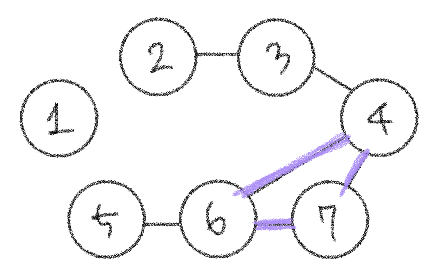
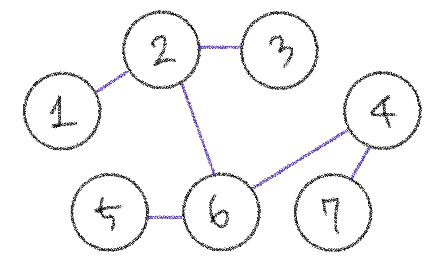
크루스칼 알고리즘
우리는 다양한 문제 상황에서 가능한 한 최소한의 비용으로 이 "신장 트리"를 찾아야 할 때가 있다. 이건 너무 책같은 설명이고... 우리는 한번쯤 모든 노드를 가장 적은 비용으로 연결해야 하는 문제 상황을 마주할 것이다. 머 예를 들면 N개의 도시들이 모두 연결되도록 두 도시 사이에 다리를 놓을 건데 건설비용이 만만치 않으므로 이를 최소로 하는 기가막힌 방법을 찾아야 하는 경우라던가
알고리즘은 다음과 같다.
𝟙. 간선 데이터를 비용에 따라 오름차순으로 정렬
𝟚. 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인
✧ 사이클이 발생하지 않는 경우: 최소 신장 트리에 포함 o
✧ 사이클이 발생하는 경우: 최소 신장 트리에 포함 x
𝟛. 모든 간선에 대해 𝟚의 과정 반복 *-*
요약하자면 ! 가장 거리가 짧은 간선부터 사용하기 위해 모든 간선들에 대해 오름차순 정렬을 수행한 뒤, 순서대로 집합에 포함시킨다는 것. (연결한다는 뜻) 근데 다 넣으면 의미가 없고, 사이클을 발생시킬 수 있는 간선이 있다면 빼고 연결하자. 이 방법이 최적의 해를 보장해준다🧚🏻♀️
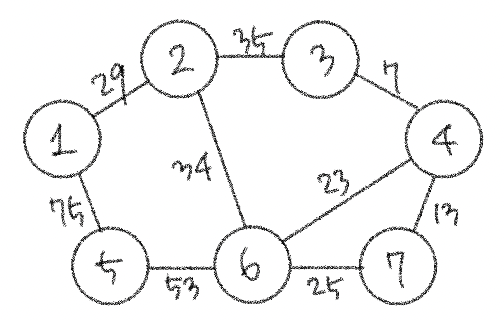
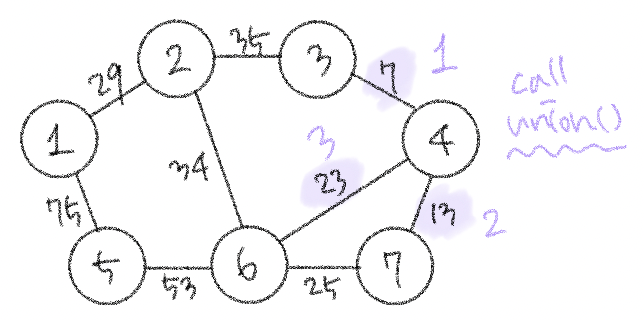
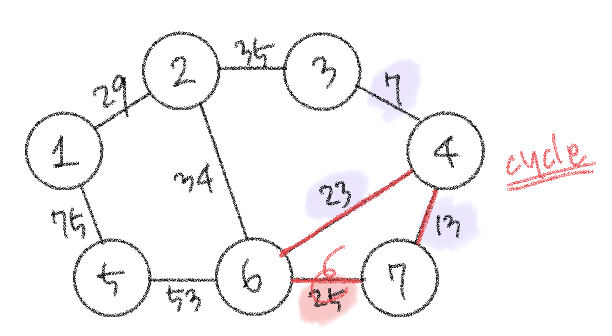
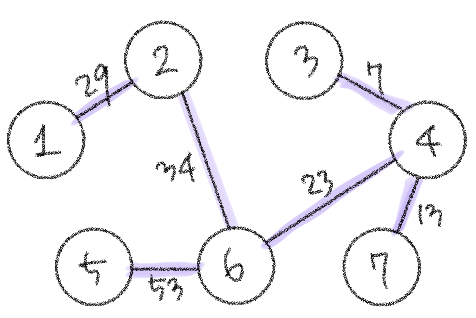
다 이해했고 다 좋은데 사이클이 발생하는 경우를 구분하는 걸 어떻게 구현할지만 고민하면 될 것 같다. . 간선이 연결하고 있는 두 노드가 이미 집합에 포함되어 있는 경우에 사이클이 발생하기 때문에 그걸 어떻게 파악할지 알아보자.
✧ 서로소 집합을 활용한 사이클 판별 ✧
이 알고리즘은 그래프에 포함되어 있는 간선의 개수가 E개일 때, 모든 간선을 하나씩 확인하며 매 간선에 대해 union 및 find 함수를 호출하는 방식으로 동작한다. a, b 노드를 연결하는 간선이 있을 때 a의 루트 노드랑 b의 루트 노드가 같으면 사이클이 발생할 것이다.
like this
# 사이클 판별 알고리즘
cycle = False
for i in range(e):
a, b = map(int, input().split())
if find_parent(parent, a) == find_parent(parent, b): # 사이클 발생
cycle = True
break
else: # 사이클이 발생하지 않았다면 합집합 수행
union_parent(parent, a, b)아무튼 이 서로소 집합을 활용한 사이클 판별 알고리즘을 적용한 크루스칼 알고리즘은 모든 간선에 대한 정보를 입력받아 사이클이 발생하지 않는 경우에만 집합에 포함시키면서 결과적으로 최소 비용을 구한다.
Kruskal.py
# 크루스칼 알고리즘
# 입력
# v e
# a, b, cost
edges.sort()
# 모든 간선을 확인하면서
for edge in edges:
cost, a, b = edge
if find_parent(parent, a) != find_parent(parent, b): # 사이클이 발생하지 않으면
union_parent(parent, a, b) # 합집합 수행
result += cost # 비용은 기록٩( ᐕ)و
시간 복잡도를 알아보자. 크루스칼 알고리즘에서 시간이 가장 오래 걸리는 부분은 간선을 정렬하는 작업이다. 그래서 간선의 개수가 E개일 때, E개의 데이터를 정렬하게 되니까 그때의 시간복잡도인 $O(ElogE)$가 이 알고리즘의 시간복잡도가 된다. (크루스칼 내부에서 사용되는 서로소 집합 알고리즘의 시간 복잡도는 정렬 알고리즘보다 작으므로 무시 가넝)
위상 정렬
Topology Sort는 sort니까 당욘 정렬 알고리즘의 일종이다. 위상 정렬은 순서가 정해져 있는 일련의 작업들을 차례대로 수행해야 할 때 사용할 수 있는 알고리즘이라고 한다. 이것도 애매한데 더 어려운말로 설명하자면, 방향 그래프의 모든 노드를 "방향성에 거스르지 않도록 순서대로 나열하는 것"이다.

이 예시처럼 커리큘럼에는 선수과목이 있다. 여기서 진입차수(Indegree)를 알아볼 수 있는데, 진입차수는 특정한 노드로 "들어오는" 간선의 개수를 의미한다. 예를 들어 두 개의 선수과목을 가지고 있는 "고급 알고리즘" 과목(노드)의 진입차수는 2이다. 이러한 진입차수를 이용해 방향에 맞게 노드들을 순서대로 나열하는 위상 정렬을 수행하는 구체적인 알고리즘은 다음과 같다.
𝟙. 진입차수가 0인 노드를 큐에 넣기
𝟚. 큐가 빌 때까지 다음의 과정 반복 *-*
✧ 큐에서 원소를 꺼내 해당 노드에서 출발하는 간선을 그래프에서 제거
✧ 새롭게 진입차수가 0이 된 노드를 큐에 넣기
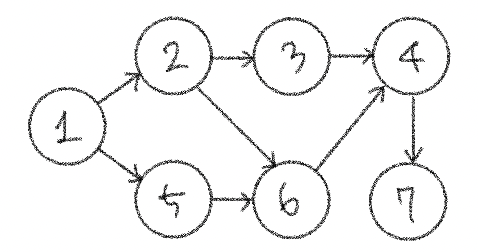
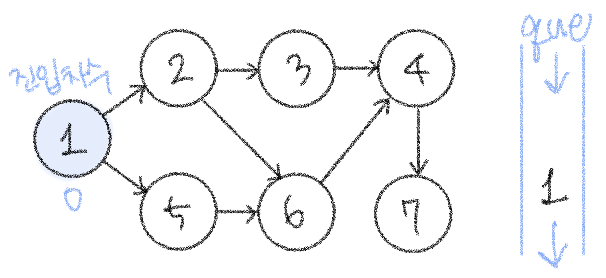
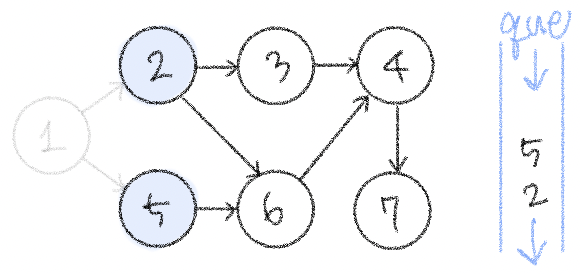
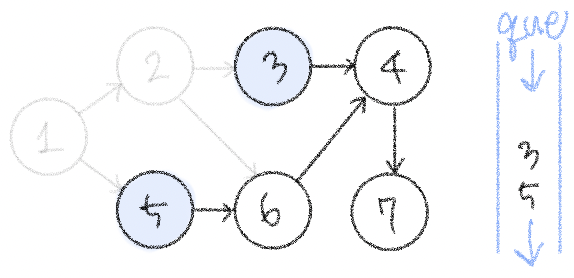
하고 나면 진입차수가 0이 되는 노드 3이 큐에 들어간다.
이런식으로 이런 규칙?을 반복하면
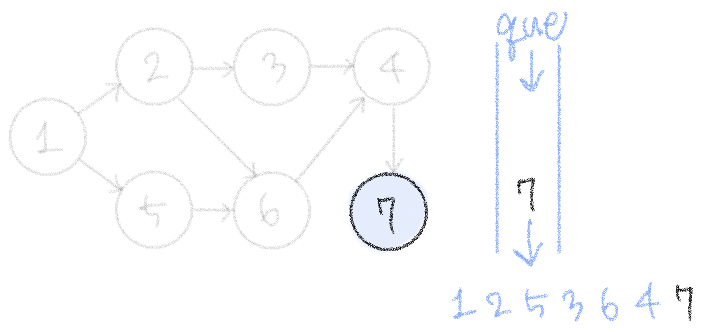
1-2-5-3-6-4-7이 위상 정렬을 수행한 결과가 되는 것이다. (사실 1-5-2-3-6-4-7도 답이 될 수 있다는 것이 위상 정렬의 특징이다) 소스코드도 함 보자 !
Topology.py
# 위상 정렬 알고리즘
# 입력
# v e
# a b
from collections import deque
v, e = map(int, input().split()) # 노드의 개수, 간선의 개수
indegree = [0] * (v+1) # 모든 노드에 대한 진입차수 0으로 초기화
graph = [[] for i in range(v+1)] # 각 노드에 대한 간선 정보를 담은 연결 리스트
# 모든 간선 정보 입력
for _ in range(e):
a, b = map(int, input().split())
graph[a].append(b) # a -> b 간선
indegree[b] += 1 # b로 들어오는 간선 개수 += 1
# 위상 정렬 함수
def topology_sort():
result = [] # 수행결과 리스트(큐에서 나오는 순서)
q = deque()
# 처음에는 진입차수가 0인 노드를 큐에 삽입
for i in range(1, v+1):
if indegree[i] == 0:
q.append(i)
# 큐가 빌 때까지
while q:
now = q.popleft() # 꺼내기
result.append(now) # 결과 리스트에 담기
for i in graph[now]:
indegree[i] -= 1 # 꺼내는 원소와 연결된 노드들의 진입차수 1 빼기
if indegree[i] == 0:
q.append(i) # 진입차수 0이면 큐에 넣기
for i in result:
print(i, end=" ")
topology_sort()٩( ᐕ)و
시간 복잡도를 알아보자. 위상 정렬을 수행할 때는 차례대로 모든 노드를 확인하면서 해당 노드에서 출발하는 간선을 차례대로 제거한다. 결과적으로 노드와 간선을 모두 확인한다는 측면에서 $O(V+E)$의 시간이 소요된다.
나동빈, ⌜이것이 취업을 위한 코딩 테스트다 with 파이썬⌟, 한빛미디어, 2020
'☃️ Study > Algorithm' 카테고리의 다른 글
| 9. 최단 경로 (0) | 2022.02.28 |
|---|---|
| 8. 다이나믹 프로그래밍 (0) | 2022.02.23 |
| 6. 여러가지 정렬 (0) | 2022.02.17 |
| 5. BFS와 DFS (2) | 2022.02.16 |


댓글