Abstract
본 논문에서는 적대적인 관계의 두 네트워크를 동시에 학습해 생성 모델을 추정하는 새로운 프레임워크, Generative Adversarial Network을 제안한다. 여기서 generative model G는 원본 데이터의 분포를 학습하고, discriminative model D는 이미지가 학습 데이터인지 G로부터 만들어진 데이터인지를 구별할 수 있도록 학습이 이루어진다. G와 D는 일종의 minimax 게임을 하며, 어떤 목적 함수가 있을 때 한쪽은 그 식을 최소화하고 다른 한쪽은 최대화하는 방향으로 학습을 진행하는 것이다. G는 D를 속이기 위해, D는 속지 않기 위해 학습을 진행하는데 이런식으로 학습을 완료했을 때 G는 학습 데이터의 분포를 잘 근사하게 된다. 본 논문에서 제안하는 방법은 기존의 특정 생성 모델에서 요구되었던 Markov chain이나 별도의 inference network가 사용되지 않아도 괜찮다. 기존 방법들과는 차이가 있는 새로운 방식으로 오직 neural network만 사용해서 학습할 수 있다는 점이 특징이다.
생성 모델(Generative Model)이란?
생성 모델은 실존하지 않지만 있을 법한 데이터(이미지, 문장 등)를 생성할 수 있는 모델을 의미함!
일반적인 분류 모델(Discriminative Model)과의 차이점은 분류 모델이 특정한 decision boundary를 학습하는 형태라면, 생성 모델은 각각의 class에 대해 적절한 분포를 학습하는 형태라는 것이다.
Generative Model produce an image that does not exist but is likely to exist
❕ A statistical model of the joint probability distribution
❕ An architecture to generate new data instances
생성 모델의 목표는?
이미지 데이터의 분포를 근사하는 모델 G를 만드는 것!
모델 G가 잘 동작한다는 의미는 원래 이미지들의 분포를 잘 모델링할 수 있다는 것을 의미함. 분포를 잘 모델링한다면 확률이 높은 부분부터 출발해서 약간의 noise를 섞어가면서 랜덤하게 sampling을 한다면 그렇게 만들어진 이미지는 굉장히 다양한 형태로 그럴싸한 이미지들이 될 것이기 때문.
~ 이러한 생성 모델 아키텍처로는 2014년에 제안된 Generative Adversarial Networks (GAN)이 대표적이고,
~ GAN으로부터 매우 다양한 논문들이 파생되었음
Introduction
딥러닝 기반의 생성 모델들은 몇가지 문제가 있었다. 예를 들어 intractable한 확률론적인 계산들은 근사하는 데에 어려움이 있었고, ReLU와 같은 piecewise linear unit들은 장점을 최대화해서 이용하기엔 어려움이 있던 상황이었다. 본 논문을 통해 제안하는 GAN의 경우 이러한 어려움들을 적절히 회피할 수 있는 새로운 방법이다. GAN은 adversarial nets라는 새로운 프레임워크를 제안하는데, 생성모델은 하나의 적군과 싸우는 방식으로 학습할 수 있다. 여기서 적군은 discriminator, 즉 판별 모델이 될 것이고, 생성자를 일종의 위조지폐범, 판별자를 위조지폐를 감별해낼 수 있는 경찰로 비유한다.
Related work
이전까지 존재했던 다양한 생성 모델을 위한 architecture들과 그러한 아키텍처에서 존재할 수 있는 어려움에 대해 설명한다 ~.~
Adversarial nets
메인 아이디어를 설명하는 챕터.
GAN이 adversarial한 네트워크인 이유는 적대적인 두 개의 네트워크, 생성자(generator)와 판별자(discriminator)를 학습하기 때문이다. 학습이 완료된 이후에 우리가 실제로 사용하고자 하는 모델은 generator이고, discriminator는 생성자의 학습을 도와주는 목적으로 사용하게 된다. 다음의 목적 함수(objective function)을 통해 이해해보자.
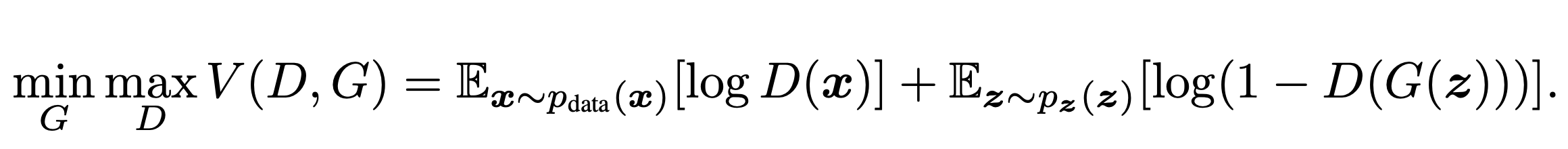
여기서 함수 V가 있을 때, 생성자 G는 V의 값을 낮추고자 하고 판별자 D는 높이려고 한다. 이때 원본 데이터의 distribution인 $p_{data}$에서 x라는 값을 sampling한 왼쪽 term은 데이터셋에서 이미지를 뽑아 넣은 기댓값을 의미한다. 여기에 생성자의 개념이 포함되는 오른쪽 term을 더해주는데, 기본적으로 생성자는 noise vector로 두고 입력을 받아 새로운 이미지를 만들 수 있다. 따라서 distribution $p(z)$에서 하나의 noise를 랜덤하게 sampling하고 이를 생성자 G에 넣어서 가짜 이미지를 만든 다음, D에 넣고 로그를 취한 값의 평균을 구해준 것이 그 식이다.
❕Generator $G(z)$: new data instance
❕Discriminator $D(x)$ = Probability: a sample came from the real distribution (Real: 1 ~ Fake: 0)
정리하자면 generator G는 하나의 노이즈 벡터인 z를 받아 새로운 image instance를 만들 수 있고, 이때 discriminator D는 이미지 x를 받아 그 이미지가 얼마나 진짜 같은지(학습 데이터 분포에서 나온 값인지)에 대한 확률 값을 출력으로 내보낸다. 판별자 D는 V를 maximize하기 때문에 로그함수를 통해 원본 데이터에 대해 1을 반환할 수 있도록 학습이 되는 것이고, 반면 가짜 이미지에 대해서는 0을 반환할 수 있도록 학습이 된다. 생성자 G의 경우 오른쪽 term에만 영향을 주고 해당 term을 minimize하기 때문에 자기가 만든 가짜 이미지가 판별자에 의해 진짜라고 인식이 될 수 있도록 (판별자가 1을 반환할 수 있도록) 그럴싸한 이미지로 보이게 하는 방향으로 학습을 진행한다.

따라서 구체적인 흐름은 위와 같다. noise vector z가 들어왔을 때, Generator를 거쳐 하나의 Fake image를 만들어낸다. 이때 목적 함수의 오른쪽 term 값을 낮춰야하기 때문에 이 값이 줄어드는 방향으로 생성자 G를 업데이트하고자 Fake image를 Discriminator에 넣어 얻은 Loss값을 G로 미분하고 이에 -learning rate을 곱한 값을 이용해 G를 반복적으로 업데이트 해준다. 그리고 Discriminator의 경우, Fake image와 Real image를 함께 받아 Real에 대해서는 1, Fake에 대해서는 0을 부여하는 방향으로 학습을 진행하는데, 전체 loss 함수를 D로 미분하고 해당 gradient 값만큼 ascending하는 방향으로 학습하게 된다.
이렇게 동일한 식에 대해 D와 G가 서로 다른 목적을 가지기 때문에 일종의 게임이론인 Min-Max 알고리즘에 기반하는 optimization 문제로 볼 수 있다. 그렇게 동일한 식에 대해 G는 minimize, D는 maximize하는 방향으로 학습을 한다면 결과적으로 생성자 G는 그럴싸한 이미지를 만들어낼 수 있는 생성 모델이 될 것이다~라는 주장이며, 논문에서는 이를 수학적인 증명으로 풀어내고 실제로 모델을 학습시켜서 그럴싸한 결과가 나오는 것까지 보여주고 있다. 실제로 학습을 진행할 때는 mini-batch 사이즈(n)만큼 데이터를 뽑아서 넣을 것이고, mini-batch마다 두 네트워크를 한번씩 학습하는 방식을 반복해서 D와 G가 각각 optimal한 point로 잘 학습할 수 있도록 유도한다.
GAN의 수렴 과정
그렇다면 위 목적함수를 어떻게 이용해서 우리의 Generator가 잘 학습할 수 있도록 하는 걸까?
GAN 공식의 목표는 다음과 같다.
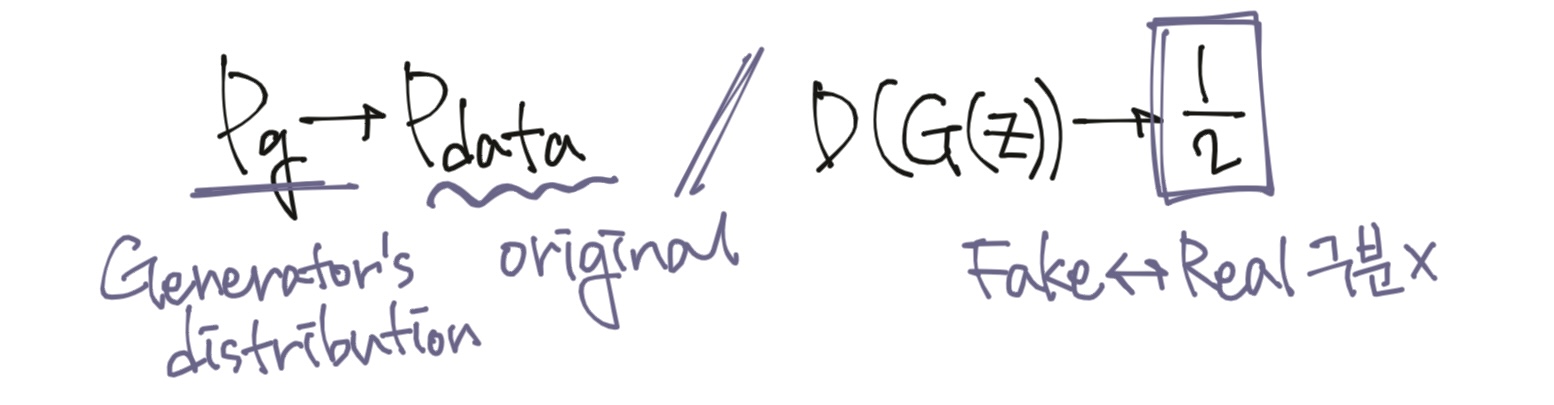
먼저 첫번째 목표는 생성자의 분포가 원본 학습데이터의 분포를 잘 따를 수 있도록 만드는 것(수렴)이고, 두번째 목표는 학습이 모두 이루어진 후에 판별자가 가짜 이미지와 진짜 이미지를 더이상 구분할 수 없게 되어 항상 50%라는 값을 내보내게 되는 것이다. 생성자가 내보낸 가짜 이미지 $G(z)$에 대해 D는 더이상 구별할 수 없다 상황을 의미한다. 이러한 과정을 시간에 따라 표현한 것이 아래의 그래프이다.

z 공간에서 매번 z를 sampling하여 생성자에 넣기 때문에 z의 domain에서 x의 domain으로 mapping이 이루어지는 모습으로 표현된다. 그리고 처음에는 (a)와 같이 생성 모델의 분포가 원본 데이터의 분포를 잘 학습하지 못했기 때문에 판별 모델인 Discriminator 또한 이미지를 잘 구분하게 된다. 그렇지만 점점 학습이 이루어짐에 따라 ~(d) 우리가 학습한 분포가 원본 데이터의 분포를 적절히 따라갈 수 있게 되기 때문에 학습이 온전히 이루어졌을 때, 판별 모델의 분포는 1/2로 수렴하게 된다.
GAN 논문에서 제시하는 목적 함수를 이용해 학습하게 되면, 위와 같은 목표를 달성함과 동시에 학습이 모두 이루어졌을 때에는 (d)의 형태로 각각의 분포가 수렴하게 될 것임을 말하고 있다. 그렇다면 학습을 진행했을 때 생성자의 분포 $P_g$가 어떻게, 그리고 왜 $P_{data}$로 수렴할 수 있는 걸까? 본 논문에서도 이 부분을 핵심 증명 포인트로 삼고 있다.
확률 분포(probability distribution)에 대하여
확률 변수가 등장할 수 있는 사건에 대한 값을 나타내기 위한 변수라면, 확률 분포는 각 사건에 대한 확률 값을 표현하는 것이다. 이미지 또한 벡터나 행렬과 같은 데이터 형태로 컴퓨터가 가지고 있을 수 있기 때문에, 다양한 확률 분포로 모델링할 수 있다. 이미지는 각 픽셀마다 RGB 3개의 채널을 가지고 있어 다차원 특징 공간의 한 점으로 표현될 수 있고, 해당 고차원 공간 상에 존재하는 분포를 학습하는 방식으로 이미지의 분포를 근사하는 모델을 학습할 수 있다.
그렇다면 이미지 데이터에 대한 확률 분포란? 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 분포를 의미한다. 예를 들어 사람의 얼굴에는 통계적인 평균치가 존재할 수 있기 때문에 모델은 얼굴의 다양한 특징들을 수치적으로 표현할 수 있고, hidden layer에서 dim을 2로 설정한다고 가정하면 캐치되는 두 개의 특징들에 대한 값을 특징공간 상에서의 다변수 확률 분포로 나타낼 수 있는 것이다.
[GAN의 수렴 과정]과 같이 모델 G의 학습이 잘 되었다면 생성 모델의 분포는 원본 데이터의 분포를 근사하게 되고, 이에 따라 통계적으로 평균적인 특징을 가지는 데이터를 쉽게 생성할 수 있게 된다. 따라서 학습 이후에는 검은색 점(원본 데이터)에 해당하지 않는 연속적인 부분들에 대해서 new data instance를 샘플링할 수 있고, 확률이 높은 부분을 중심으로 하여 노이즈를 섞어가며 데이터를 뽑아내면 그럴싸한 새로운 이미지가 만들어지는 것이다. (2014 GAN 논문에서는 세부적인 컨트롤까지 할 수 있는 방법을 제안하고 있지는 않지만 원본 GAN 논문 이후에 발전된 method들이 등장하면서 현재는 세부적인 특징들을 잘 컨트롤 할 수 있는 형태로 다양한 GAN 모델들이 제안되었다)
Theoretical Results
❕How can the formulation lead $P_g$ converge to $P_{data}$?
실제로 학습을 진행했을 때, $P_g$가 $P_{data}$로 수렴하게 되는지를 증명하기 위해 가장 먼저 Global Optimality를 증명한다.
이는 매 상황에 대해 생성자와 판별자가 각각 어떤 포인트에서 global optimal을 가지는지를 수학적으로 구하는 과정이다.
먼저 아래와 같이 목적함수 V를 다른 식으로 치환함으로써 주어진 명제를 증명하고 V를 최대화하는 optimal discriminator D를 구한다.

그렇다면 이제 우리가 궁극적으로 알고자 하는 내용인 생성자의 global optimum point가 어디인지 알아보자.
앞서 설명했듯이, 학습이 진행됨에 따라 생성자의 분포는 원본 데이터 distribution을 따라가게 된다.
따라서 다음의 명제를 증명하는 방식으로 구할 수 있을 것이다.
❕Proposition: Global optimum point is $p_g = p_{data}$

위와 같이 식을 변형시켜줌으로써 이 부분의 두 term을 KL divergence로 치환할 수 있다. KL divergence는 두 개의 분포가 있을 때, 두 분포가 얼마나 차이나는지를 수치적으로 표현하기 위해 일반적으로 사용할 수 있는 공식이다. 따라서 $P_{data}$와 $P_g$에 대한 분포의 차이를 KL divergence로 표현한 공식을 이용하면 두 기댓값을 더한 위의 식을 다음과 같은 형태로 표현할 수 있다.

이러한 수식의 변환은 증명의 편의성을 위한 것인데, 일반적으로 KL divergence의 경우 distance metric으로 활용하기 어렵다. 따라서 JSD로 변환해 distance metric으로 사용하는 것이다. 이때 JSD는 두 개의 분포, p와 q가 있을 때 이 두 분포의 distance를 구하는 데에 사용한다. 해당 공식을 그대로 활용해서 치환했던 2개의 KL divergence 값을 한개의 JSD divergence term으로 바꿔줄 수 있고, 이때 JSD는 distance metric이기 때문에 그 최솟값을 0으로 가진다는 점이 특징이 된다. 다시 말하면 $p_g = p_{data}$일 때 0이라는 값을 가지게 되어 사라지므로 우리는 최솟값으로 $-log(4)$를 얻을 수 있는 것이다.
따라서 global optimum point를 얻을 수 있도록 해주는 유일한 솔루션은 생성자의 분포와 $p_{data}$가 동일할 때, 즉 우리의 생성자가 만들어내는 이미지가 원본 data distribution과 동일할 때가 된다. 이렇게 매번 D가 이미 잘 수렴해서 global optimal이라고 가정한 상태에서 생성자가 잘 학습된다면 $-log(4)$와 같은 값을 가질 수 있도록 잘 수렴하여 $p_{data}$와 같은 분포를 가지는 형태가 될 것이다~라며 생성자와 판별자 각각에 대해 global optimum point가 존재할 수 있다는 것을 증명한 내용이다. 학습이 잘 되어 global optimal에 잘 도달할 수 있는가는 또 다른 문제이고, 이렇게 GAN은 학습이 어려운 네트워크 중 하나로 추후 다른 논문들을 통해 학습의 안정성을 높일 수 있는 테크닉들이 나왔다고 한다.
실제 구현 알고리즘은 다음과 같다.

Experiments
- Not cherry-picked: 논문의 이미지들은 별도로 선별해서 넣은 이미지가 아닌, 랜덤하게 만든 것
- Not memorized the training set: 학습 데이터를 단순히 암기한 것이 아님을 보여주기 위해, n-1번째 column과 nearest neighbor인 학습 데이터를 뽑아 마지막 nth column으로 추가해서 보여주고 있음
- Competitive with the better generative models: 다른 생성 모델들과 비교했을 때의 성능을 보여줌
- Images represent sharp: auto-encoder 계열의 다른 생성 네트워크와 비교했을 때 상대적으로 blurry 하지 않음을 말함
+) latent space상에서 선형적으로 interpolation을 해서 data를 sampling. 1을 만들 수 있는 latent vector와 5를 만들 수 있는 latent vector 사이에서 interpolation을 수행하고, 매번 실제 이미지로 바꿔보는 과정을 통해 자연스럽게 있을 법한 이미지들을 거쳐 각 이미지가 latent space 상에 존재함을 보여줌. latent space에서 만들어지는 이미지들은 semantic한 정보를 유지하면서 변형될 수 있다는 것
Reference
동빈나씨의 GAN 리뷰 영상을 보고 이해하고 정리한 내용임니다. https://youtu.be/AVvlDmhHgC4
'☃️ Study > Paper' 카테고리의 다른 글
| Attention is all you need (0) | 2023.08.16 |
|---|---|
| AlexNet 논문 리뷰 (2) | 2023.08.02 |


댓글