Intro
Attention은 NLP에서 처음 나온 개념이다. 우리는 문장에서 주어를 연결시키고, 그 주어가 어떤 행동을 했다는 걸 파악할 수 있다. 그거슨 인간이기 때문에 당연하다....기보단 우리가 그 주어를 유추하기 위해 문장 전체가 아니라 특정 단어들에 focusing을 해서 판단하기 때문이다. 그래서 attention은 인간이 뭔가를 이해할 때 사용하는 그 집중을 모방한다. 다시 말하면... 어떤 데이터가 연속되어 들어왔을 때, 특정 데이터를 판단함에 있어서 전체를 다 regular하게 참조하는게 아니라, 제일 연관성이 있어 보이는 부분을 가져와서(중요한 것 같은 데이터에 focusing해서) 특정 데이터가 무엇인지 판단하겠다~는 개념을 사용한게 attention이다.
Attention을 이해하기 위해 먼저 value vector를 이해해보자

위와 같이 어떤 단어를 넣으면, word embedding이라는 알고리즘을 통해 벡터로 만들 수 있다. 이는 living being, feline, human과 같은 몇개의 카테고리를 제시하고 그 기준(token)으로 판단했을 때, 단어와의 연관성에 따른 가중치를 표현한 것이다. 예를 들어 cat이라는 단어에 대해 주어진 카테고리별로 평가를 하면 cat을 나타내는 벡터가 나오는데, 이때 이 벡터는 cat의 고유 벡터라고 할 수 있고 이와 마찬가지로 문장을 넣으면 해당 문장을 벡터화할 수 있다는 것이다.
문장을 벡터화(vectorization)한다는 것은 내가 이 문장을 해석가능한 어떤 숫자의 집합이나 차원으로 가져온다는 것을 뜻한다. 이에 따라 각 token들이 축이 되어, 이 7개의 축 상에 존재하는 친구를 정의할 수 있게 된다. 그래서 비슷한 느낌의 cat과 kitten은 카테고리화 결과 그 수치가 비슷할테니 거의 비슷한 영역에 존재하게 됨을 볼 수 있고, 이렇게 비슷한 특징을 가지는 친구들이 비슷한 영역에 있도록 만들어주는 것이 바로 word embedding이다.
그리고 이렇게 벡터화를 수행한 다음, 그 결과를 평가해서 나와 연관있는 친구를 찾는게 Attention이다 ~
Attention
"weight가 높다 == 나와 연관이 많다"에 따라 이 가중치를 계산하기 위해서는 다음의 세가지 정보를 가져야 한다.
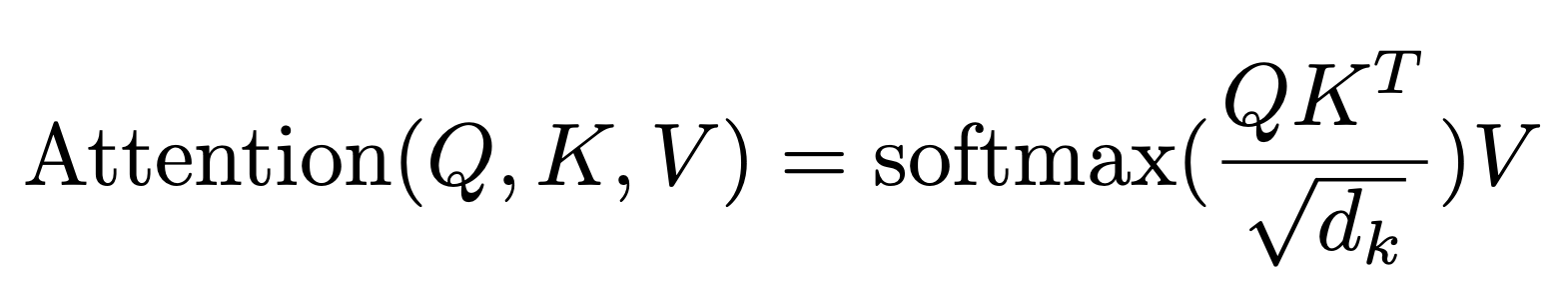
Q는 current token으로, 내가 판단할 대상이 된다. K와 V는 둘 다 Q와의 관계를 나타내는 token이고, $d_k$는 embedded vector의 dimension을 의미한다. 다음 예시를 통해 attention을 구하는 과정을 알아보자.
❕The animal didn’t cross the street, because it was too tired.
이러한 연속된 데이터가 들어왔을 때, 지칭대명사인 it이 animal과 연관이 많다는 것을 나타내려면 animal과의 weight가 높을 것
먼저 it을 위에서 설명한 word embedding을 통해 3차원 벡터로 보내고, 지금 it이랑 관련있는 애가 누구야~라고 구하는거니까, 내가 구하고자하는 녀석을 쿼리로 설정함.
it과 관련된 친구가 누구인지 구하고 있는거니까 물음을 표하는 대상인 it을 Query로 설정한다. 여기서 QK-1을 계산해서 하나의 attention score로 만들고, 차원수로 나눠주는 건 차원이 너무 크면 학습이 안되니까 데이터 정규화 목적으로 나눠줌.


지금까지 it과 animal 사이의 attention score만 구했지만 전체에 대한 attention을 구하고 싶은거니까, 전체문장의 각 단어들에 대한 attention을 구하기 위해 다음과 같이 함. 이렇게 query와 key를 모두 곱해서 it과 모든 단어들에 대한 관계를 나타내는 attention score 벡터를 구함. 여기에 softmax를 적용하고, value를 한번 더 곱해주면 최종적으로 문장 전체에 해당하는 attention에 대해 뭉개진 value가 나옴
이걸 또 it만을 대상으로 하지 않고, 각 단어에 대해 문장 전체에서 어떤 관계가 있는지 찾아 최종적으로 query attention을 만듬
self~에 대한 설명
Transformer
transformer의 핵심 구성요소인 self attention에 대해 알아보자
근데 사실 위에서 사용했던 예시가 self attention이었음. 그렇기에 self attention이 아닌 예시에 대해 생각해보자면,
Q, K, V를 모두 같은걸 사용했을 때 self attention이라고 하는데,
지금까지는 query에 대해 누구랑 가장 관련있는지를 찾았다면, self attention은 이 문장 내에서 내가 뭐랑 가장 연관이 있는지를 찾는 것이다.
예를 들어 the는 누구랑 연관이 있지? animal은 누구랑 연관이 있지?
일반적인거랑 뭔 차이냐면... "나랑 다른 데이터를 가져왔을 때 연관성을 찾는 걸 말한다." 위 문장에서 "동물"이라는 단어와 가장 연관이 있는걸 찾는게 self attention인 것 (그래서 번역에 사용되었음...)
그래서 SOMA에서 들어온 데이터를 판단함에 있어서 해당 point cloud가 머리인가?를 판단해야 하는데 self attention을 사용하면, 주변데이터를 보아하니~ 얘랑 가장 연관이 많은 데이터는 ~이 친구들인거 같은데 ~로 미루어보아 판단했을 때 얘는 머리가 맞는거같아. 라는 판단을 하기 위함.
Reference
https://cpm0722.github.io/pytorch-implementation/transformer
↳ 이 글로 이해했고, 게임공학 수업 필기본을 기반으로 작성했슴니다.
'☃️ Study > Paper' 카테고리의 다른 글
| GAN 논문 리뷰 (0) | 2023.08.09 |
|---|---|
| AlexNet 논문 리뷰 (2) | 2023.08.02 |


댓글